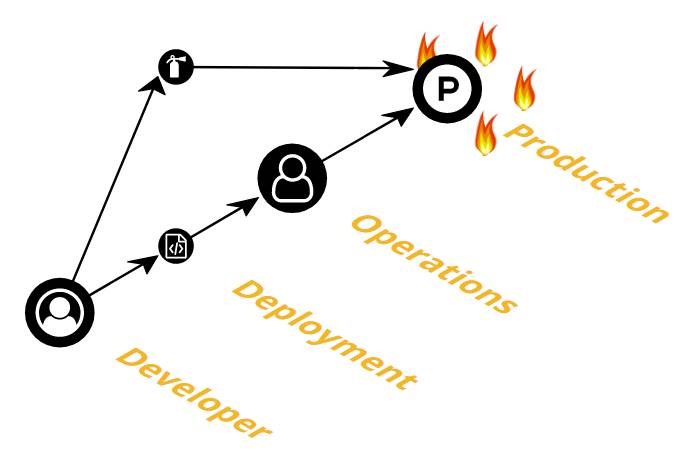
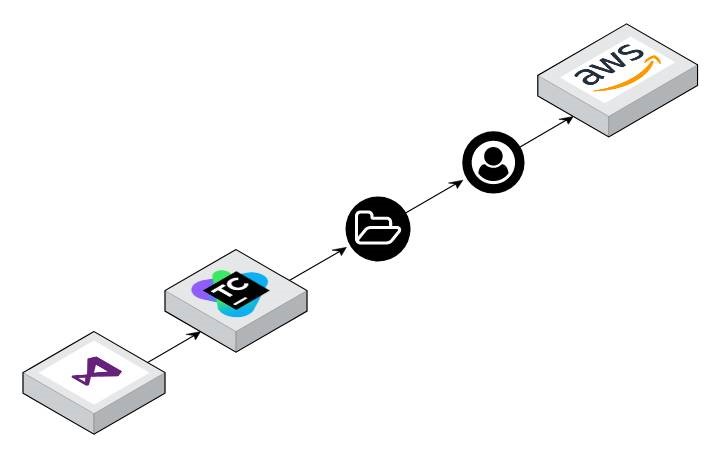
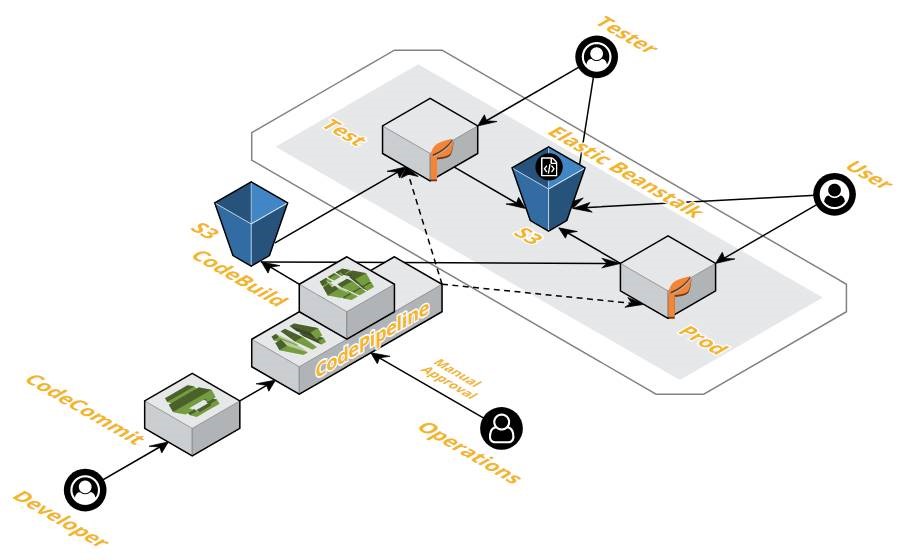
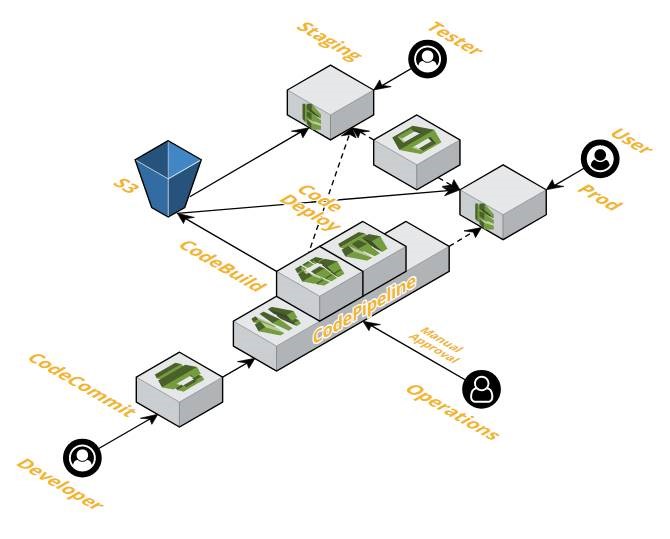
Innovative Solutions is a mid-sized company, but many times we encounter communication and coordination problems at an enterprise scale. Internally, we have multiple development teams with each team comprised of multiple team members bringing a range of skill sets. Each team interacts with third-party vendors, providers, and clients who often bring their own development teams with whom we collaborate. Quite often clients are directly communicating with third parties as well. As the number of entities in this communication graph increases, the complexity of organizing and interacting grows which requires structures and processes to be put in place to ensure efficient communication.
Over the years we have been employing and maturing our SDLC methodologies, following Agile practices, and incorporating the latest tools to help develop, deploy, and support our products and our clients. This has organically led us to leverage DevOps services driven by industry leaders including Amazon Web Services (AWS).
Innovative Solutions takes these ideas very seriously and their adoption has helped us successfully navigate an increasingly complex ecosystem. In fact, Innovative takes this so seriously we require any engagement to be working toward an end goal of leveraging DevOps processes and tools. We’ve seen time and time again when our partners understand the value in laying a proper foundation, and we all win.
Leveraging automated build and CI pipelines has taken a burden off developers freeing them to spend more time creating rather than waiting to see if tests pass. We heavily use AWS CloudFormation to automate our infrastructure setup in a repeatable manner. This makes spinning up a temporary lower environment almost instantaneously, with just one-click versus the weeks it took just a few years ago.
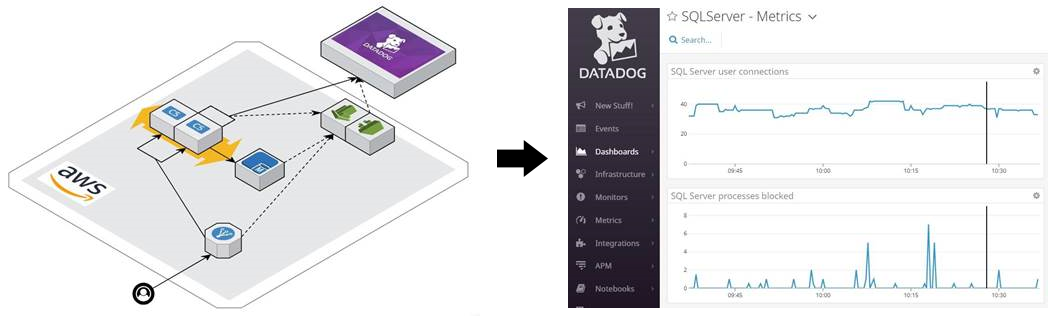
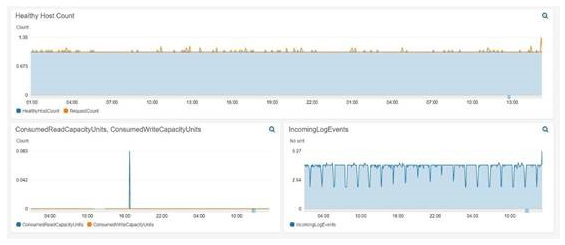
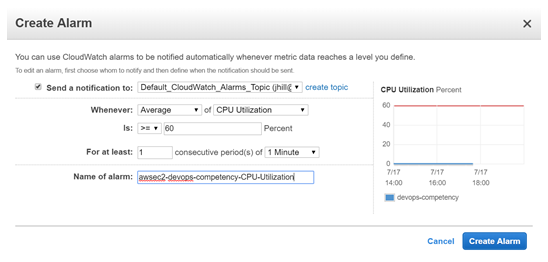
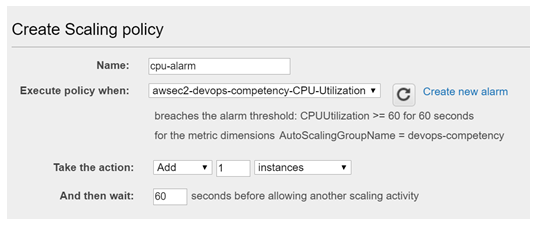
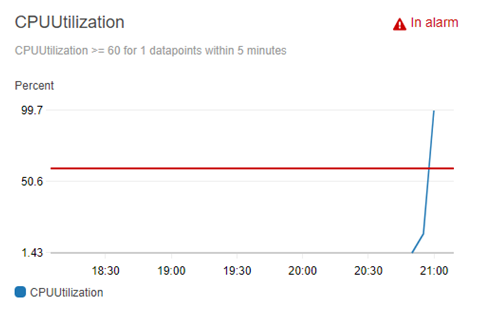
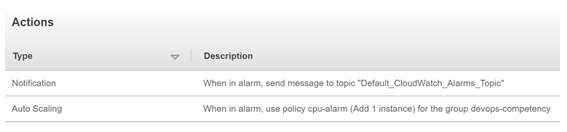
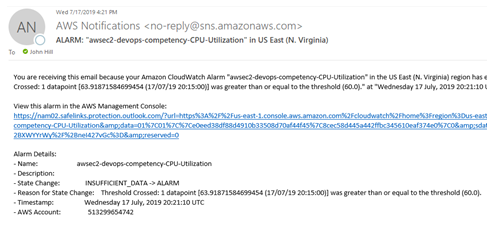
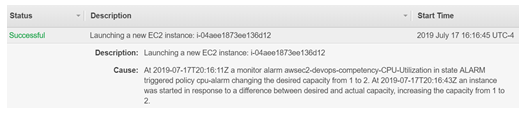
Advanced monitoring and alerting enables Innovative’s team to identify small problems before they become big ones. Tools like Amazon CloudWatch, AWS X-Ray, and Datadog provide visibility into systems unparalleled to anything we had in the past. We now leverage logs and metrics that previously were discarded to identify areas of opportunity so we can continually improve customer experience while providing tangible value to our clients.
DevOps and Regulation
The complexities of interactions these days are exacerbated by ever-growing regulatory pressures. Innovative Solutions consistently partners with customers who must adhere to HIPAA, PCI, SOCs, and other compliances. Innovative has utilized AWS DevOps tools to create processes and controls making compliance and audits more secure and successful.
The same build and deploy pipelines that facilitate our rapid development cycles also provide immutable packages we can promote from environment to environment. This helps us ensure that no bad actors have the ability to tamper with code on its way to production.
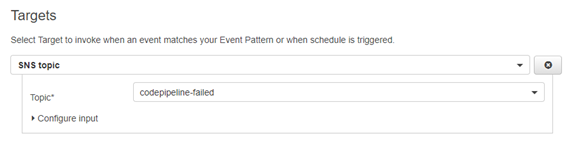
We leverage AWS CodePipeline’s manual approvals ensuring releases have the appropriate sign-off before moving forward. This allows us to put in place appropriate controls and separation of duties.
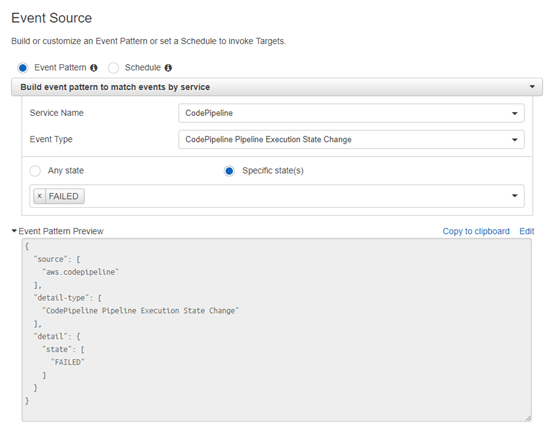
AWS Config gives us the capability to be notified when any part of our infrastructures deviates from the policies we have defined. If this happens, AWS CloudTrail makes it easy to perform root-cause-analysis and correct the problem quickly. Our applications are assessed by Amazon Inspector to identify any deviations from internal standards.
A Must-Have for Any Business
DevOps is not something off on the horizon. The methodologies and tools are mature enough that it should be considered as part of the standard SDLC. If you’re not already practicing DevOps, the time is now. DevOps is not a nice-to-have, but a must-have for any business serious about long-term software development.
Do you still have questions about DevOps?
Feel free to contact us, we’d love the opportunity to further discuss anything you have read.